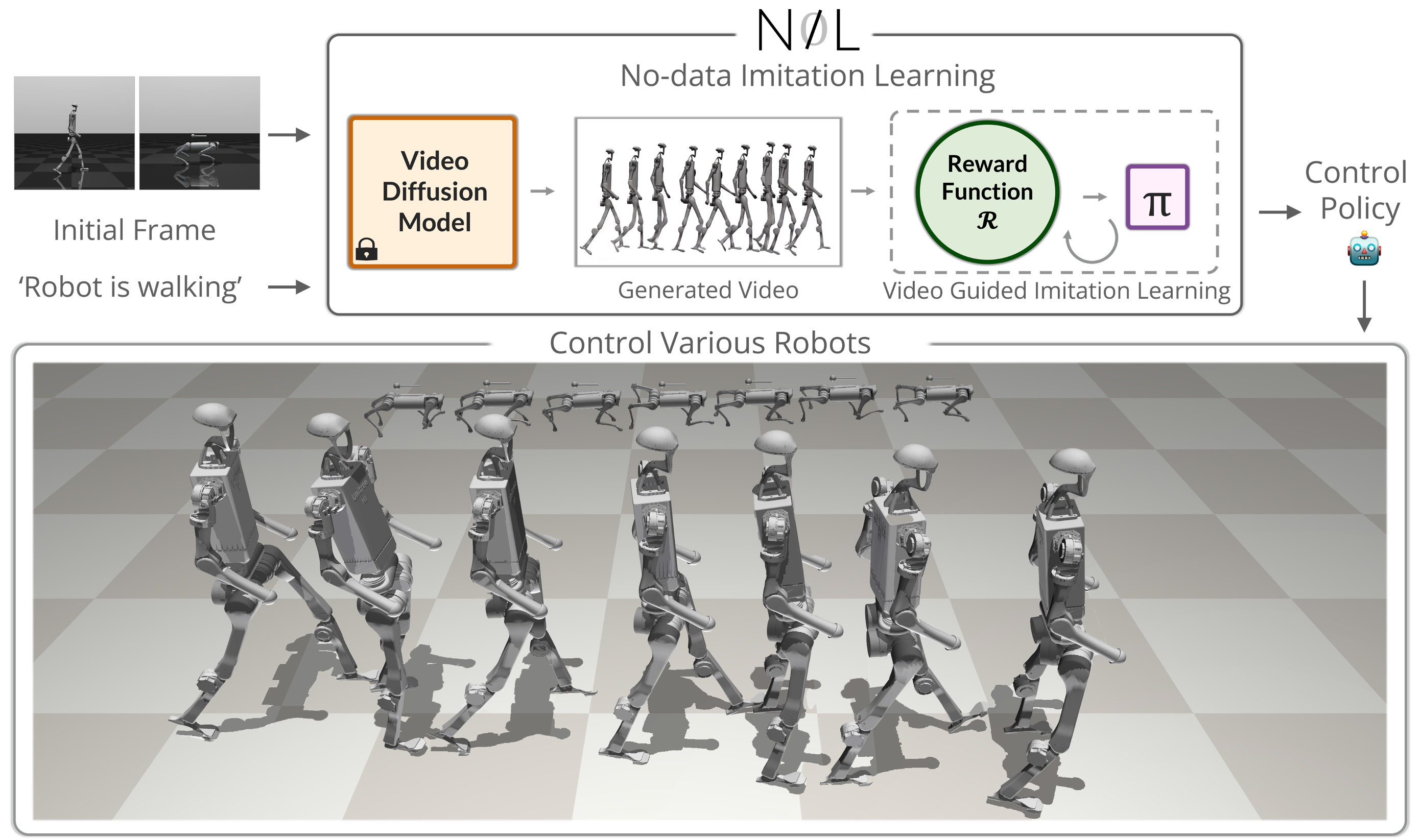
Teaching robots motor skills using only AI-generated videos; no motion capture, no expert demonstrations, no curated data. Just a text prompt and a physics simulator.
A short walkthrough of how NIL works, the results, and why it matters.
Current approaches to robot learning face fundamental bottlenecks. NIL eliminates them all.
Requires painstaking manual reward engineering for each new task and robot. Poorly specified rewards lead to unintended behavior.
Needs expensive, high-quality 3D motion-capture data. Challenging to obtain for non-humanoid robots and animals.
Uses AI-generated videos as the sole source of demonstration. No curated data, just a text prompt.
Key Insight: Video diffusion models generate realistic-looking motion for any morphology. While these videos aren't physically accurate, a physics simulator can enforce plausibility. NIL combines both; the video provides visual guidance, the simulator enforces physical constraints.
NIL generates a reference video from a text prompt, then trains a control policy to physically replicate it in simulation.
Render the robot's initial frame. Feed it with a task description (e.g., "Robot is walking") into a pretrained video diffusion model. Generate a realistic 2D video of the desired motion.
Train a reinforcement learning policy in a physics simulator to match the generated video. The reward compares the simulation rendering against the reference video using video encoders and segmentation masks.
NIL computes a discriminator-free imitation reward by comparing the rendered simulation against the generated video through three complementary signals.
A video vision transformer (TimeSFormer) embeds both videos. Cosine similarity between their embeddings provides temporal and semantic guidance.
Segment the robot's body in both videos using SAM2. Compute frame-by-frame IoU between masks for precise spatial alignment.
Penalize excessive joint torques, angular velocities, and action deltas to ensure smooth, stable, physically plausible motion.
NIL learns locomotion for four different robots from a single generated video each. Left: AI-generated reference. Right: physically-plausible learned policy.
Kling AI — "The H1 robot is walking"
Learned natural bipedal gait
Kling AI — heavy-duty humanoid
Learned walking for complex morphology
Kling AI — compact humanoid
Learned compact humanoid locomotion
Pika — quadruped robot
Same method, four-legged gait
NIL matches AMP's performance despite using zero motion-capture data, while AMP requires 25 curated trajectories per robot.
NIL tackles whole-body manipulation — sitting, hanging, balancing — matching RL baselines that use hand-designed reward functions.
We systematically analyze each component of NIL to understand its contribution.
Each reward component contributes to final quality. Video similarity provides the strongest standalone signal, but all together yield the best result.
Best result
Jittery motion
Distorted behavior
Slow, jittery
Fails to walk straight
Cannot walk
Walks but stops
Generated by Kling

NIL works across multiple video diffusion models. Better visual quality directly translates to better policies.
Best quality → Best NIL
Resulting policy

As video diffusion models improve, NIL directly benefits. Kling v1.0 vs v1.6 shows how better quality yields more natural gaits.
Unbalanced, asymmetric
Learns but with artifacts
Natural, symmetric gait
Significantly more natural
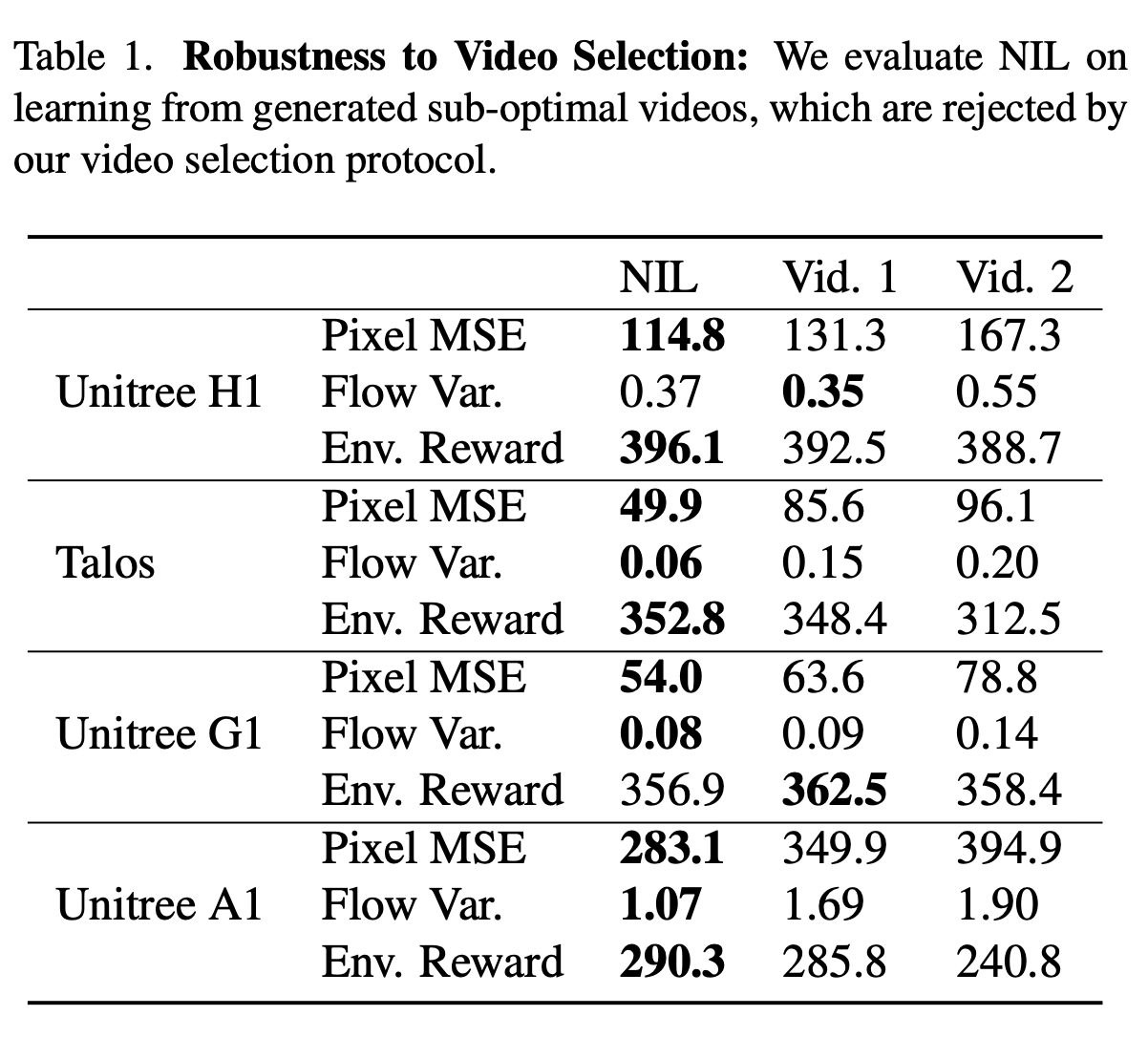
We generate 3 videos per prompt and select the best via optical flow variance and pixel MSE. Training on rejected (sub-optimal) videos shows only mild degradation, indicating NIL is robust to imperfect generations.
NIL is reproducible without proprietary video models. Training with open-source diffusion models (WAN, LTX) yields strong performance, confirming the approach is not dependent on any specific commercial API.

NIL remains strong under different camera settings: static views, 45° azimuth rotation, field-of-view jitter (5%/15%), and multi-view setups. Multi-view even improves performance on some robots.

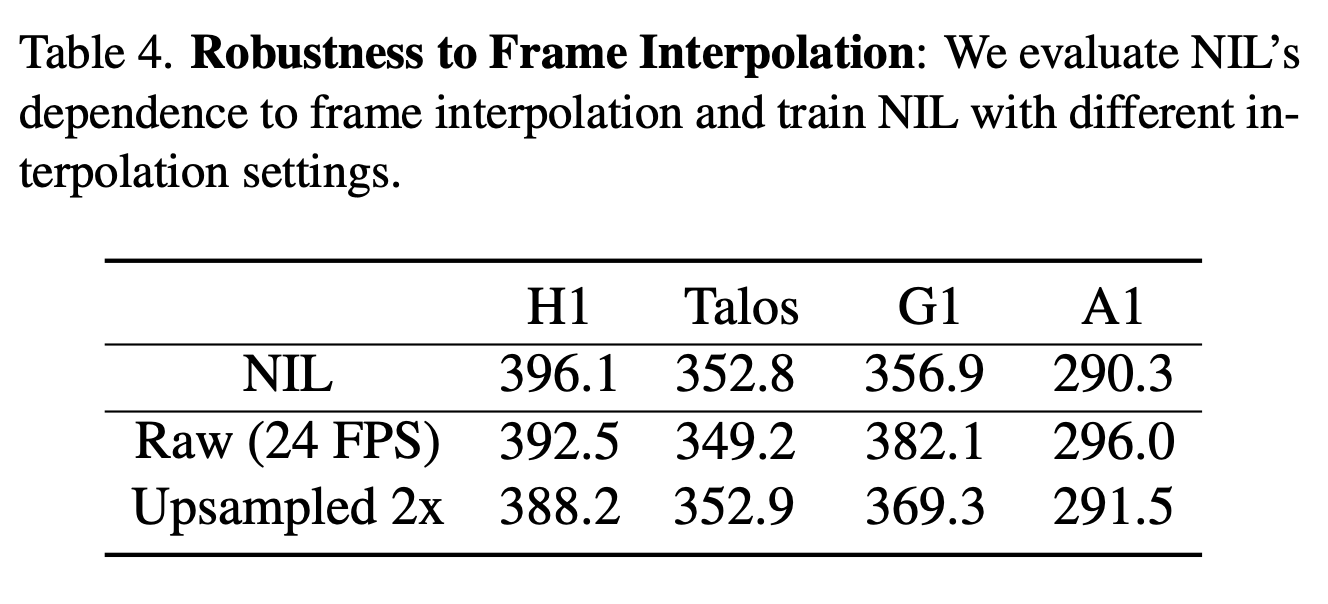
Generated videos run at 24 FPS while simulations render at 100 FPS. NIL upsamples via frame interpolation. Testing without upsampling or with alternative rates shows the method is robust to temporal resolution choices.
@inproceedings{albaba2025nil,
title={NIL: No-data Imitation Learning},
author={Albaba, Mert and Li, Chenhao and Diomataris, Markos and Taheri, Omid and Krause, Andreas and Black, Michael J.},
booktitle={IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2026}
}